miniDB
Introduction
A simple implementation of a multi-attribute linear-hashed file structure database
Structure
A MALH relation R is represented by 3 physical files:
- R.info
Containing global information
- a count of the number of attributes
- the depth of main data file (d for linear hashing)
- the page index of the split pointer (sp for linear hashing)
- a count of the number of main data page
- the total number of tuples (in both data and overflow page)
- the choice vector (cv for multi-attribute hashing)
- R.data
Containing data pages
- offset of start of free space
- overflow page index (or NO_PAGE if none)
- a count of the number of tuples in that page
- the tuples (as comma-separated C strings)
- R.ovflow Containing overflow pages, which have the same structure as data pages
When a MALH relation is first created, it is set to contain a \(2^n\) pages, with depth \(d=n\) and split pointers \(sp=0\). The overflow is initially empty.
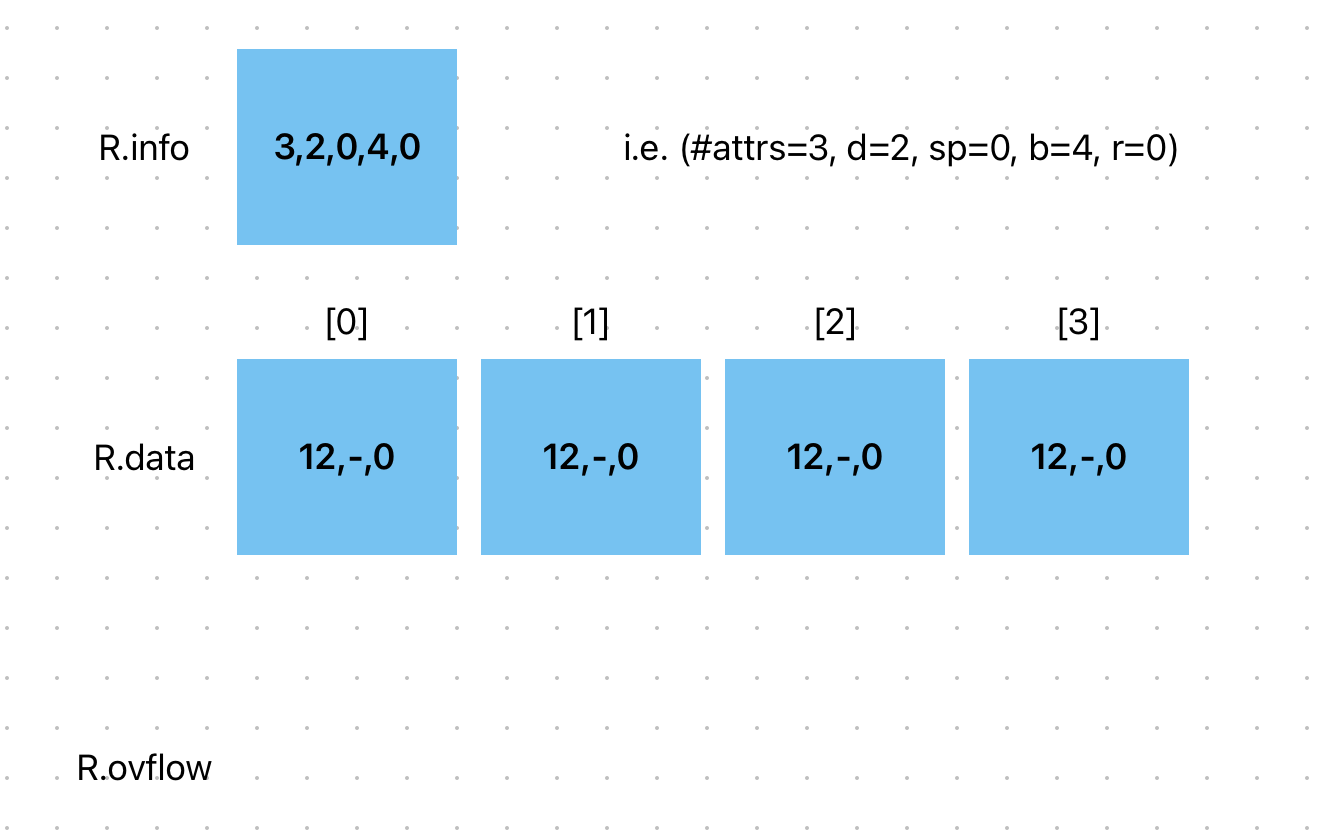
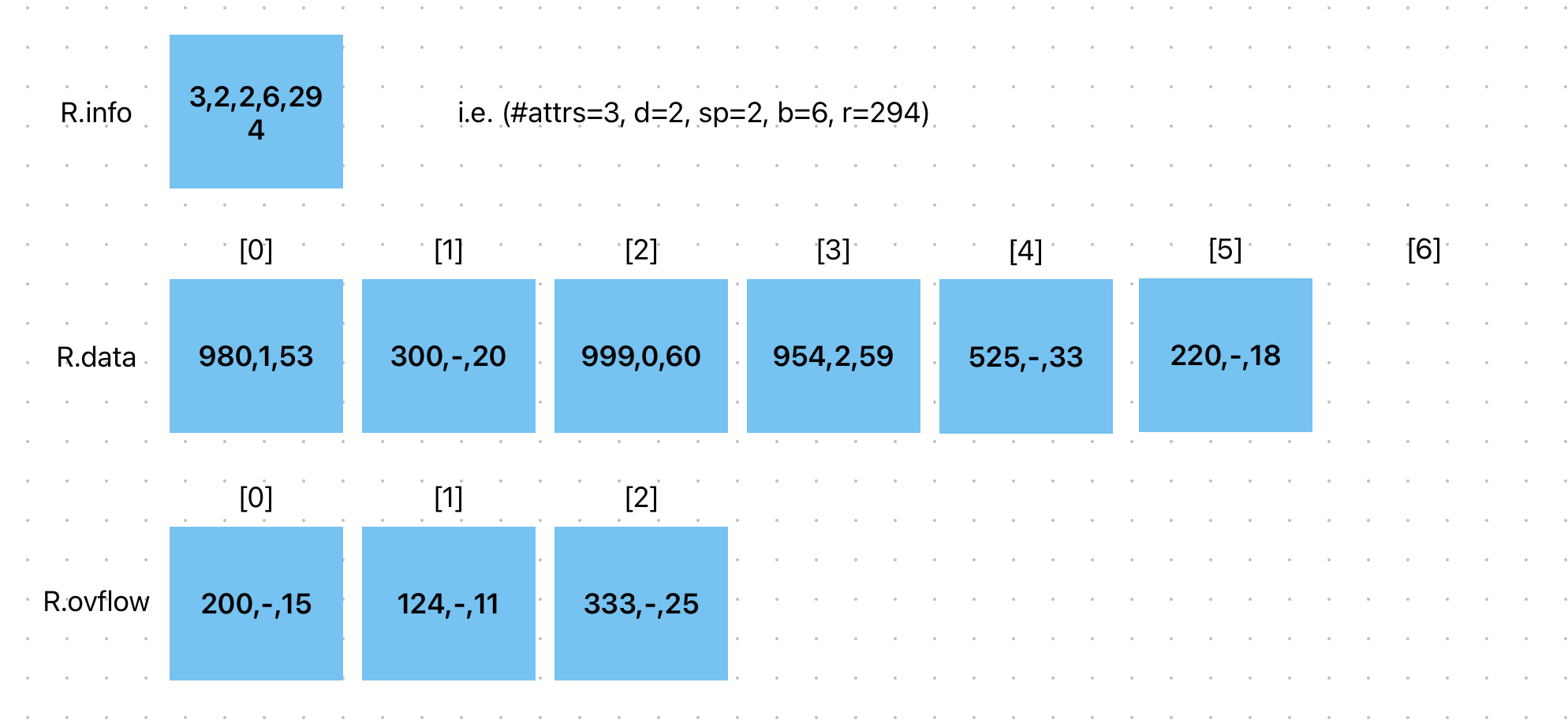
After 294 tuples have been inserted, the file becomes (depending on field value distributions, tuple sizes, etc):
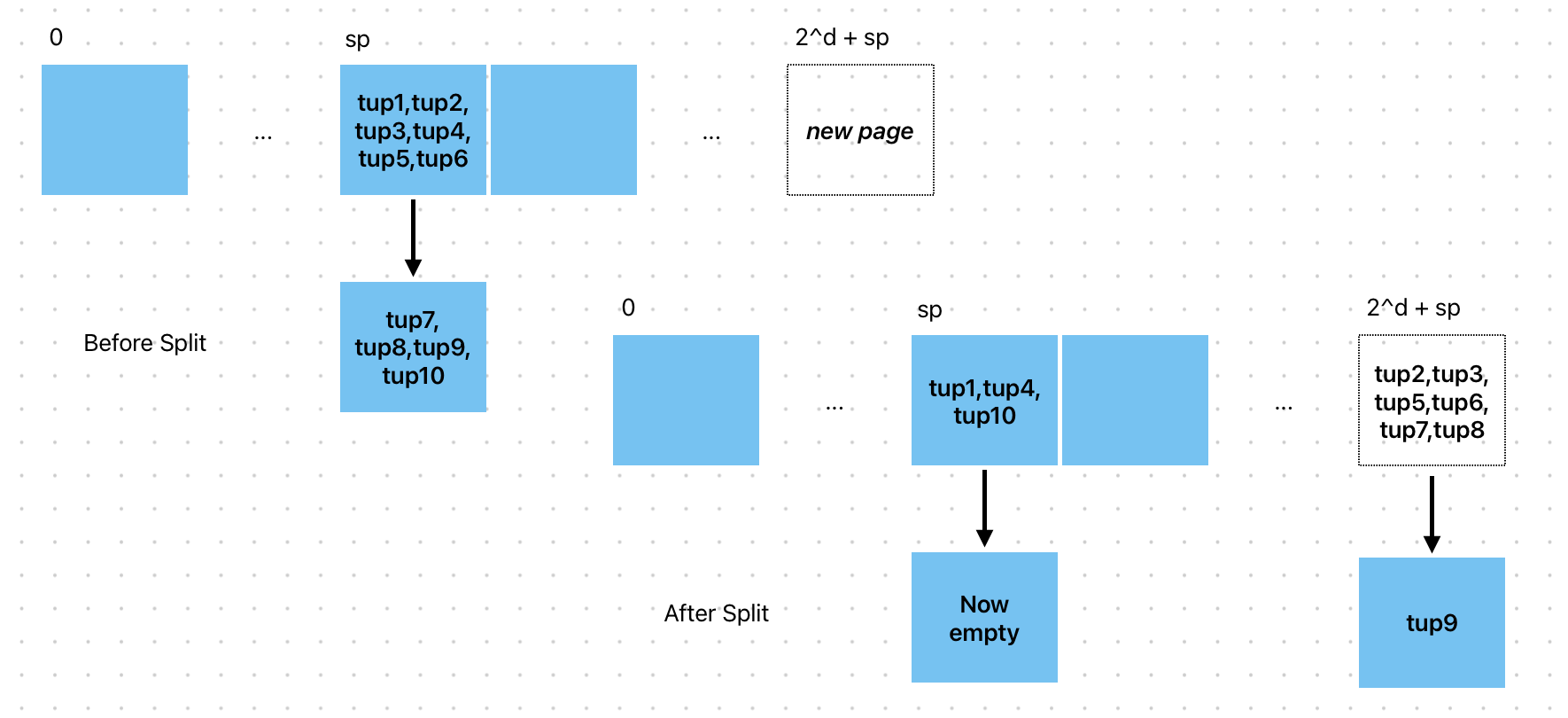
Example of a page split:
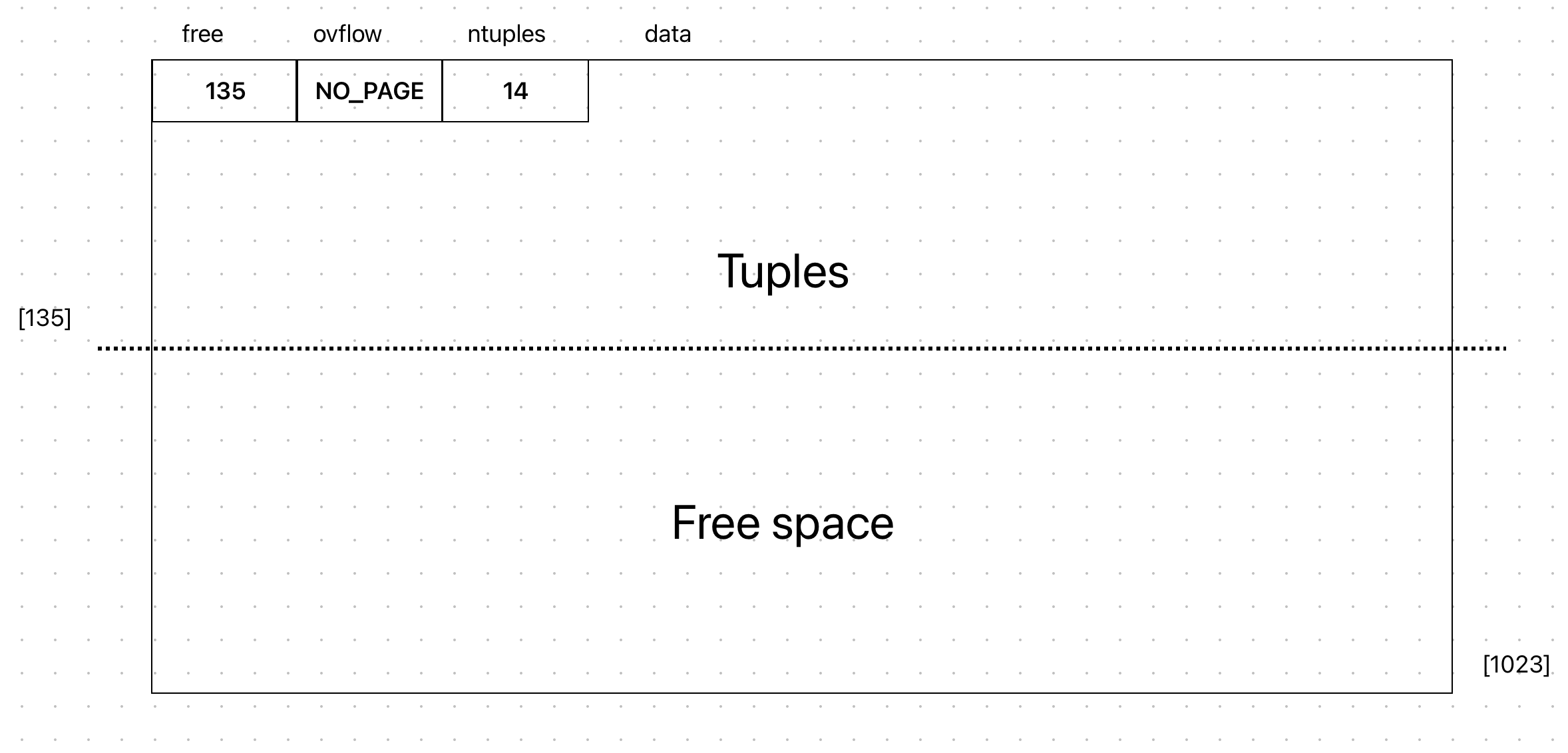
Pages in MALH files have the following structure: a header with three unsigned integers, strings for all of the tuple data, free space containing no tuple data.
Commands
Create
Creates MALH (multi-attribute linear-hashed) files by accepting 4 command line arguments:
- the name of the relation
- the number of attributes
- the initial number of data pages (rounded up to nearest 2n)
- the multi-attribute hashing choice vector
Example:
$ ./create R 4 6 "0,0:0,1:1,0:1,1:2,0:3,0"
makes a table called abc with 4 attributes and 8 inital data pages (6 will be rounded up to the nearest 2n)
The choice vector (4th argument):
- bit 0 from attribute 0 produces bit 0 of the MA hash value
- bit 1 from attribute 0 produces bit 1 of the MA hash value
- bit 0 from attribute 1 produces bit 2 of the MA hash value
- bit 1 from attribute 1 produces bit 3 of the MA hash value
- bit 0 from attribute 2 produces bit 4 of the MA hash value
- bit 0 from attribute 3 produces bit 5 of the MA hash value
Insert
Reads tuples, one per line, from std input and inserts them into the relation.
The bucket where the tuple is stored is determined by the appropriate number of bits of the combined hash value. If the relation has \(2^d\) data pages, then \(d\) bits are used. If the specified data page is full, then the tuple is inserted into an overflow page of that data page.
Example:
$ echo "100,xyz,abc" | ./insert R
# prints the hash value for the tuple
Query
Run selection and projection queries over a given relation. It supports wildcard and pattern matching, finds all tuples in either the data pages or overflow pages that match the query, as well as flexible attribute projection without distinct
Example:
$ ./query [-v] 'a1,a2,...' from RelName where 'v1,v2,...'
- ‘a1,a2,…’ (or ‘*’): a sequence of 1-based attribute indexes used for projection, can be ‘*’ to indicate all attributes. The minimal ‘a’ value is ‘0’
- ‘v1,v2,…‘: a sequence of attribute values used for selection
Each $v_i$ in the selection tuple can be:
- Literal value: A specific value that must match exactly in the corresponding attribute position. (e.g., ‘xyz’ matches ‘xyz’, ‘64’ matches ‘64’)
- Single question mark ‘?’: Matches any literal value in the corresponding attribute position. (e.g., ‘?’ matches ‘xyz’, ‘?’ matches ‘64’)
- Pattern string containing ‘%’: A string that includes one or more’%’, where each ‘%’ matches zero or more characters.
$ ./query '*' from R where '?,?,?'
# matches any tuple in R
$ ./query '3, 1' from R where '10,?,?'
# projects attribute 1 and 3 in order from tuples where attribute 0 is 10
$ ./query '*' from R where '?,%xz%,?'
# matches any tuple where attribute 1 contains 'xz'
Status
Check the status of the files for table R with stats command:
$ ./stats R
# prints out the stats of R
dump
Show tuples, bucket-by-bucket
$ ./dump [RelName]
gendata
Use gendata to generate large numbers of tuples, and insert them as:
$ ./gendata 800 3 100 | ./insert R
Insert 800 tuples into the table, with ID values starting at 100.
clean
Remove Rel.data Rel.info Rel.ovflow. If no argument provided, remove every existing relation.
$ ./clean [RelName]